添加仓库
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts拉取chart到本地
helm fetch prometheus-community/prometheus --untar对 chart 内 quay.io 进行批量替换 quay.nju.edu.cn 进行加速
部署
进入解压后的 prometheus文件夹
准备配置自定义配置文件override_values.yaml
主要涉及 prometheus 的端口暴露31003方便外部访问和开启了 kube-state-metrics 的监控方便监控集群资源状态
server:
service:
annotations: { }
labels: { }
clusterIP: ""
## List of IP addresses at which the Prometheus server service is available
## Ref: https://kubernetes.io/docs/user-guide/services/#external-ips
##
externalIPs: [ ]
loadBalancerIP: ""
loadBalancerSourceRanges: [ ]
servicePort: 8080
nodePort: 31003
sessionAffinity: None
type: NodePort
nodeExporter:
hostRootfs: false
kubeStateMetrics:
## If false, kube-state-metrics sub-chart will not be installed
##
enabled: true
## kube-state-metrics sub-chart configurable values
## Please see https://github.com/prometheus-community/helm-charts/tree/main/charts/kube-state-metrics
##
kube-state-metrics:
prometheus:
monitor:
honorLabels: true
image:
registry: ccr.ccs.tencentyun.com
repository: tkeimages/kube-state-metrics
pullPolicy: IfNotPresent
tag: "2.2.4"
部署
helm upgrade prometheus -n prometheus-system --set alertmanager.enabled=true --set server.persistentVolume.enabled=false -f override_values.yaml --create-namespace --install .如果需要持久化建议开启server.persistentVolume.enabled=true
可以考虑安装 rancher动态卷来提供local pv
wget https://raw.githubusercontent.com/rancher/local-path-provisioner/v0.0.27/deploy/local-path-storage.yaml对涉及的 dockerhub 镜像增加前缀 docker.m.daocloud.io/ 加速,然后执行
kubectl apply -f local-path-storage.yaml更新部署 prometheus
helm upgrade prometheus -n prometheus-system --set alertmanager.enabled=true --set server.persistentVolume.enabled=true -f override_values.yaml --create-namespace --install .检查
# kubectl get all -n prometheus-system
NAME READY STATUS RESTARTS AGE
pod/prometheus-alertmanager-0 1/1 Running 0 6m9s
pod/prometheus-kube-state-metrics-77849c4465-rxb9l 1/1 Running 0 7m48s
pod/prometheus-prometheus-node-exporter-4tzqg 1/1 Running 0 7m48s
pod/prometheus-prometheus-node-exporter-8zg8g 1/1 Running 0 7m48s
pod/prometheus-prometheus-node-exporter-k8854 1/1 Running 0 7m48s
pod/prometheus-prometheus-pushgateway-c8d68cdc7-g9s2m 1/1 Running 0 7m48s
pod/prometheus-server-977d6b88-ph6h6 2/2 Running 0 7m48s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/prometheus-alertmanager ClusterIP 10.233.24.122 9093/TCP 7m48s
service/prometheus-alertmanager-headless ClusterIP None 9093/TCP 7m48s
service/prometheus-kube-state-metrics ClusterIP 10.233.14.27 8080/TCP 7m48s
service/prometheus-prometheus-node-exporter ClusterIP 10.233.59.145 9100/TCP 7m48s
service/prometheus-prometheus-pushgateway ClusterIP 10.233.51.109 9091/TCP 7m48s
service/prometheus-server NodePort 10.233.38.81 8080:31003/TCP 7m48s
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/prometheus-prometheus-node-exporter 3 3 3 3 3 kubernetes.io/os=linux 7m48s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/prometheus-kube-state-metrics 1/1 1 1 7m48s
deployment.apps/prometheus-prometheus-pushgateway 1/1 1 1 7m48s
deployment.apps/prometheus-server 1/1 1 1 7m48s
NAME DESIRED CURRENT READY AGE
replicaset.apps/prometheus-kube-state-metrics-77849c4465 1 1 1 7m48s
replicaset.apps/prometheus-prometheus-pushgateway-c8d68cdc7 1 1 1 7m48s
replicaset.apps/prometheus-server-977d6b88 1 1 1 7m48s
NAME READY AGE
statefulset.apps/prometheus-alertmanager 1/1 7m48s 访问
部署后可以通过节点ip:31003 访问 prometheus 自带的面板
具体配置可以访问节点 ip:31003/config
配置修改
如果需要修改配置可以参考 chart 里的 values.yaml 然后在override_values.yaml 中进行修改,比如里面可以在 serverFiles.alerting_rules.yml 配置告警 ,在 serverFiles.recording_rules.yml配置 recording rules
serverFiles:
## Alerts configuration
## Ref: https://prometheus.io/docs/prometheus/latest/configuration/alerting_rules/
alerting_rules.yml: {}
# groups:
# - name: Instances
# rules:
# - alert: InstanceDown
# expr: up == 0
# for: 5m
# labels:
# severity: page
# annotations:
# description: '{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes.'
# summary: 'Instance {{ $labels.instance }} down'
## DEPRECATED DEFAULT VALUE, unless explicitly naming your files, please use alerting_rules.yml
alerts: {}
## Records configuration
## Ref: https://prometheus.io/docs/prometheus/latest/configuration/recording_rules/
recording_rules.yml: {}
## DEPRECATED DEFAULT VALUE, unless explicitly naming your files, please use recording_rules.yml
rules: {}在extraScrapeConfigs 配置其他采集任务
# adds additional scrape configs to prometheus.yml
# must be a string so you have to add a | after extraScrapeConfigs:
# example adds prometheus-blackbox-exporter scrape config
extraScrapeConfigs: ""
# - job_name: 'prometheus-blackbox-exporter'
# metrics_path: /probe
# params:
# module: [http_2xx]
# static_configs:
# - targets:
# - https://example.com
# relabel_configs:
# - source_labels: [__address__]
# target_label: __param_target
# - source_labels: [__param_target]
# target_label: instance
# - target_label: __address__
# replacement: prometheus-blackbox-exporter:9115recording rules 配置
这里以recording rules为例,增加recording_rules 到override_values.yaml 中
serverFiles:
## Records configuration
## Ref: https://prometheus.io/docs/prometheus/latest/configuration/recording_rules/
recording_rules.yml:
groups:
- name: node.rules.30s
interval: 30s
rules:
- record: cpu_usage_active
expr: 100 - (avg by (instance) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100)
- record: mem_usage_active
expr: 100*(1-node_memory_MemAvailable_bytes/node_memory_MemTotal_bytes)
server:
service:
annotations: { }
labels: { }
clusterIP: ""
## List of IP addresses at which the Prometheus server service is available
## Ref: https://kubernetes.io/docs/user-guide/services/#external-ips
##
externalIPs: [ ]
loadBalancerIP: ""
loadBalancerSourceRanges: [ ]
servicePort: 8080
nodePort: 31003
sessionAffinity: None
type: NodePort
nodeExporter:
hostRootfs: false
kubeStateMetrics:
## If false, kube-state-metrics sub-chart will not be installed
##
enabled: true
## kube-state-metrics sub-chart configurable values
## Please see https://github.com/prometheus-community/helm-charts/tree/main/charts/kube-state-metrics
##
kube-state-metrics:
prometheus:
monitor:
honorLabels: true
image:
registry: ccr.ccs.tencentyun.com
repository: tkeimages/kube-state-metrics
pullPolicy: IfNotPresent
tag: "2.2.4"
然后更新部署
helm upgrade prometheus -n prometheus-system --set alertmanager.enabled=true --set server.persistentVolume.enabled=true -f override_values.yaml --create-namespace --install .访问节点 ip:31003/rules 可以发现 recording rules 已经生效,我们通常用 recording rules 来配置耗时任务后台定时运行以便查询时有更快的返回速度。
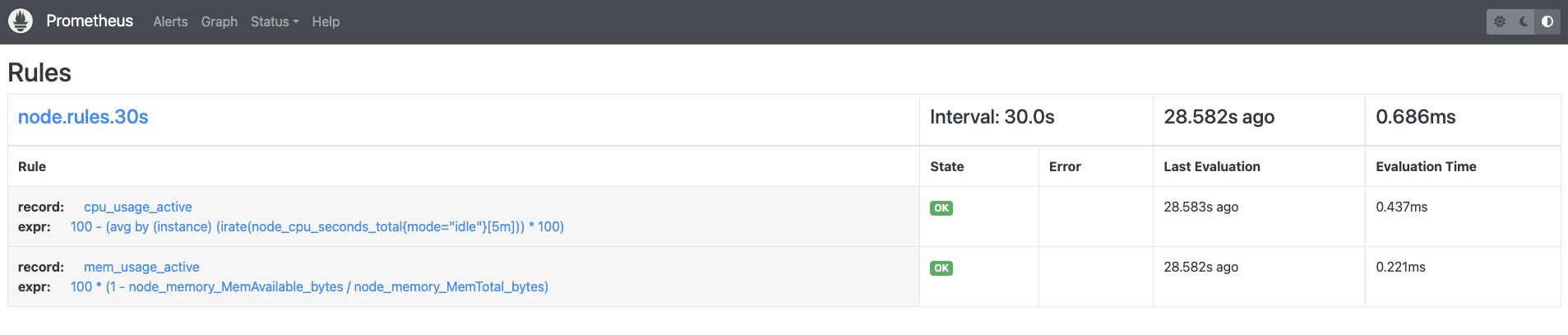
可以直接用上面的 record name进行检索
