使用场景:Prometheus 采用 pull 模式,可能由于不在一个子网或者防火墙原因,导致 Prometheus 无法直接拉取各个 target 数据。
启动命令:
/usr/local/pushgateway/pushgateway –persistence.file=/var/lib/pushgateway.db –persistence.interval=30s
–persistence.file 持久化文件,如果为空则只存在内存中
–persistence.interval 持久化周期时长,默认5分钟
Prometheus抓取配置:
scrape_configs:
- job_name: 'pushgateway'
honor_labels: true
static_configs:
- targets: ['localhost:9091']
honor_labels: true
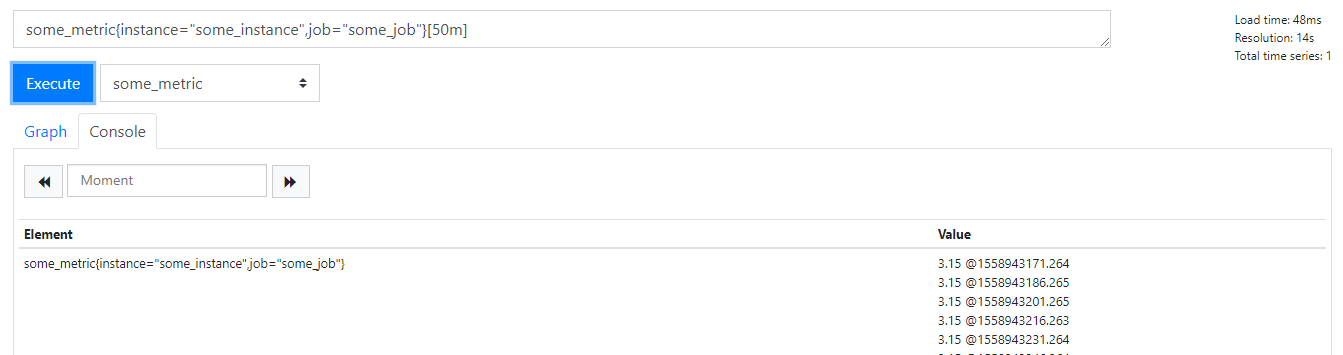
因为 Prometheus 配置 pushgateway 的时候,也会指定 job 和 instance, 但是它只表示 pushgateway 实例,不能真正表达收集数据的含义。所以在 prometheus 中配置 pushgateway 的时候,需要添加 honor_labels: true 参数,
从而避免收集数据本身的 job 和 instance 被覆盖。
客户端命令行测试:
echo “some_metric2 3.15” | curl –data-binary @- http://127.0.0.1:9091/metrics/job/some_job/instance/some_instance
echo “some_metric 3.15” | curl –data-binary @- http://127.0.0.1:9091/metrics/job/some_job/instance/some_instance
Pushgateway界面:
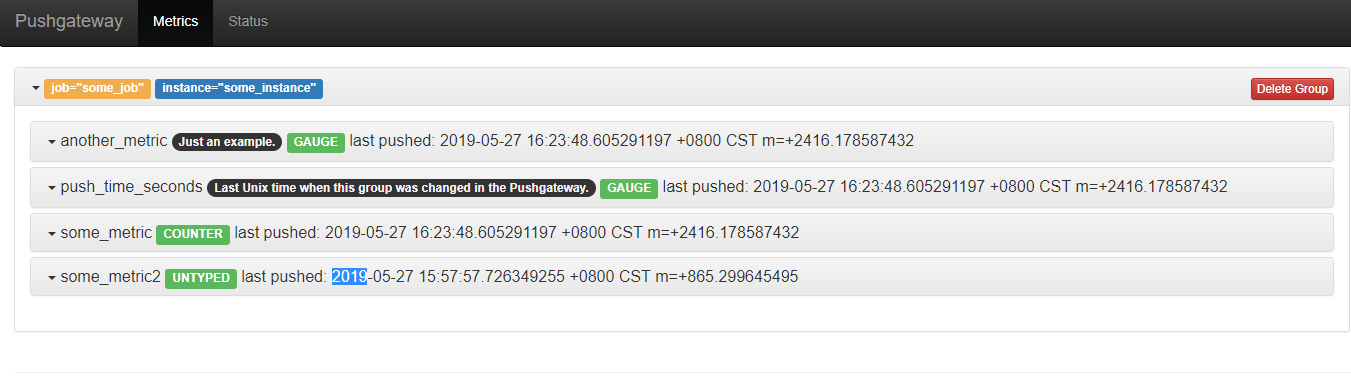
未配置honor_labels: true时
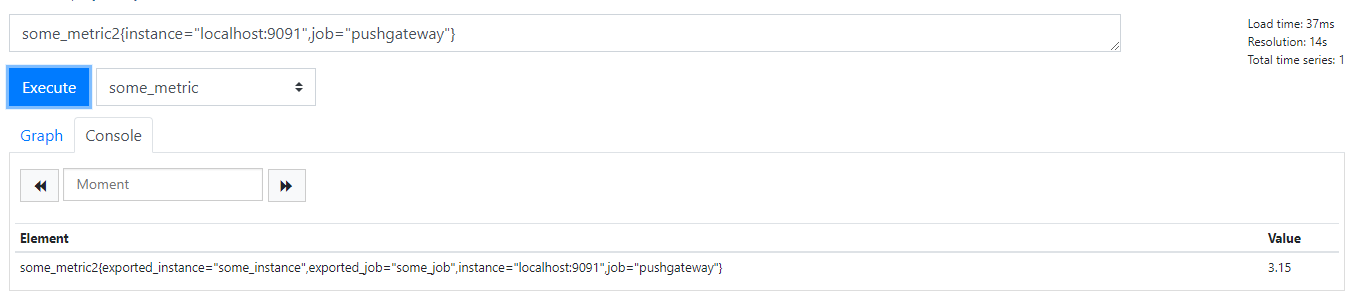
配置honor_labels: true时
缺点:
- 当采用Pushgateway获取监控数据时,Pushway即会成为单点以及潜在的性能瓶颈
- 丧失了Prometheus的实例健康检查功能(基于up指标)
- 除非手动删除Pushgateway的数据,否则Pushgateway会一直保留所有采集到的数据并且提供给Prometheus。
优点:
- 和一般exporter不同可以暂存瞬时数据,在Prometheus拉取能力不足时起到一个缓冲的效果,如果配合改造Prometheus源码能够采集后删除Pushgateway的冗余数据理论上可以做到秒级监控。(注:博主还是认为用推队列消费的方式来秒级监控更为合理扩展能力也更好)
其他:
- Pushgateway内的客户端的push ,post,delete操作不会立刻生效,操作会进入队列等待生效,所以数据不会立刻可查或者持久化
- delete作为一个空操作不会返回错误
- 所有成功操作均响应返回码 202
更多:https://github.com/prometheus/pushgateway
转运维了吗
没有