ℹ️ 本文是三篇系列文章中的第一篇。每篇文章讲涵盖map中的不同部分。建议您按顺序阅读。
Go提供的内置类型map实现了一个哈希表。 在本文中,我们将探讨此哈希表不同部分的实现:桶(存储键/值对的结构),哈希(这些键/值对的索引)和负载因子(判断 map 是否应该扩容的指标)。
桶
Go将键/值对存储在桶列表中,其中每个桶将容纳8对,而当map容量不足时,哈希桶的数量将翻倍。 这是具有4个桶的map的粗略示意图:
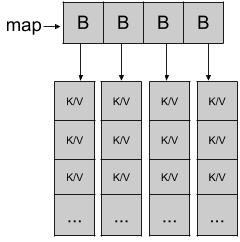
我们将在下一篇文章中看到桶中的键/值对是如何存储的。 如果map再次增长,则桶数将翻倍至8,然后是16,依此类推。
当一个键/值对进入map时,它将根据从键计算出的哈希值将其分配到桶中。
哈希
当一个键/值对被分配给map时,Go将基于这个键生成一个哈希值。
让我们举一个插入键/值对"foo" = 1的示例。生成的哈希值可能是15491954468309821754。此值将应用于位操作,掩码相较于桶数减1。在我们使用4个桶的示例中,掩码3,位操作如下:
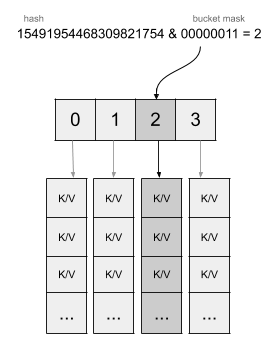
哈希值不仅用于桶中值的分配,还参与其他的操作。每个桶都将其哈希值的首字节存储在一个内部数组中,这使得 Go 可以对键进行索引,并跟踪桶中的空槽。让我们看一下哈希在二进制表示下例子:
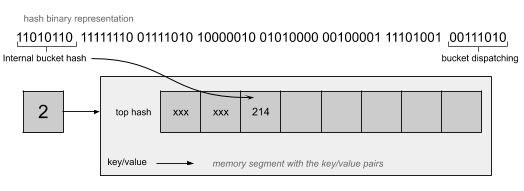
由于桶中有一个名为top hash的内部表,Go将能够在数据访问期间使用它们,并将其与请求的键的哈希值进行比较。
根据我们在程序中对 map 的使用,Go 需要对 map 进行扩容,以便管理更多的键/值对。
Map 扩容
如果桶收到要存储的键/值对,它将存储在桶中的8个可用插槽中。 如果它们都不可用,那么将创建一个溢出桶并将其链接到当前桶:
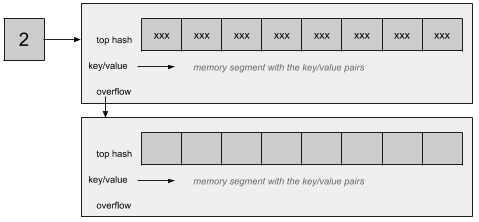
这里溢出属性表明了桶的内部结构。然而增加溢出桶会降低map的性能。为了解决这个问题,Go将会分配新桶(当前桶数的两倍),在新旧桶之间保持链接,并逐步迁移桶。实际上,在进行了新分配后,每个参与过写操作的桶,如果操作还未完成,都将被迁移。被迁移的桶中的所有键/值对都将被重新分配到新桶中,这意味着,先前同一个桶中存储在一起的键/值对,现在可能被分配到不同的桶中。
Go 使用负载因子来判断何时开始分配新桶并迁移旧桶。
Loading factor
Go选择6.5作为map的负载因子。你可以在代码中发现负载因子的相关研究:
// Picking loadFactor: too large and we have lots of overflow // buckets, too small and we waste a lot of space. I wrote // a simple program to check some stats for different loads: // (64-bit, 8 byte keys and values) // loadFactor %overflow bytes/entry hitprobe missprobe // 4.00 2.13 20.77 3.00 4.00 // 4.50 4.05 17.30 3.25 4.50 // 5.00 6.85 14.77 3.50 5.00 // 5.50 10.55 12.94 3.75 5.50 // 6.00 15.27 11.67 4.00 6.00 // 6.50 20.90 10.79 4.25 6.50 // 7.00 27.14 10.15 4.50 7.00 // 7.50 34.03 9.73 4.75 7.50 // 8.00 41.10 9.40 5.00 8.00 // // %overflow = percentage of buckets which have an overflow bucket // bytes/entry = overhead bytes used per key/value pair // hitprobe = # of entries to check when looking up a present key // missprobe = # of entries to check when looking up an absent key
如果每个桶中的值的平均数量超过6.5,则map将增长。 正如我们在研究中看到的那样,由于基于键的哈希值的分布无法平均分布,因此选择接近8的值可能会导致大量的溢出桶。
⏭ 这个系列的下一篇文章,将会讲解 map 的内部实现。
编译自https://medium.com/a-journey-with-go/go-map-design-by-example-part-i-3f78a064a352