内容目录
配置结构
在全局配置中采集配置结构中 ScrapeConfigs 代表了所有的采集 jobs, ScrapeConfig 代表了一个 job, ScrapeConfig 内discovery.Configs中的 Config代表了 job 内的一个服务发现配置。

每一个 Config对应了一个Provider, 每个Provider包含一个 Discoverer 实例
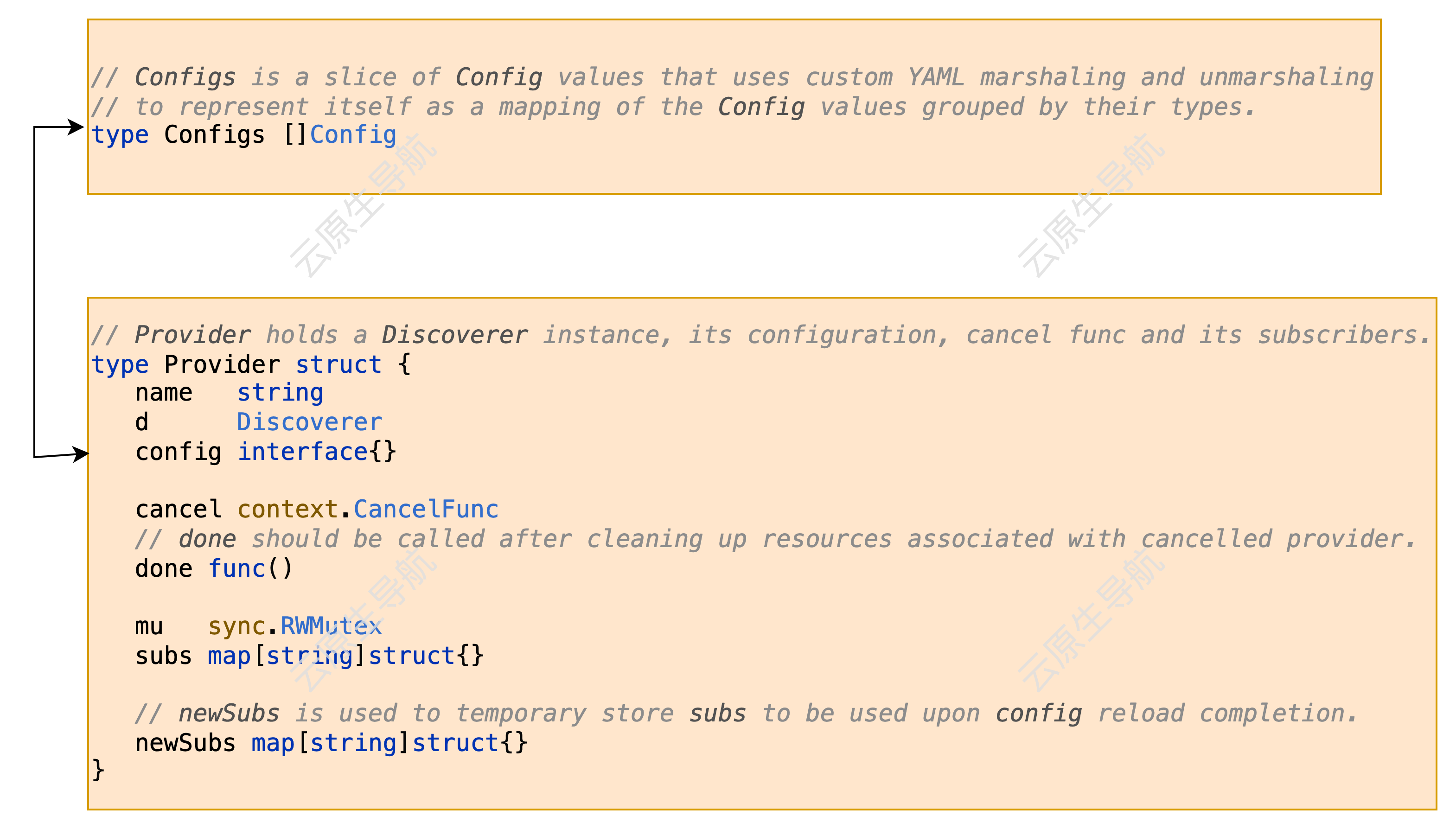
Discoverer本身是一个接口,prometheus 为每个实现单独一个文件夹,具体实现比如consul、file、zk、kubernetes 等,均需实现 Run 方法,通过 up 这个 chan 来传递发现结果

数据流转
provider在启动时会传入 updates 这个 chan 也就是上面提到的 up,这里的 p.d 就是上面提到的Discoverer,也就是服务发现的具体实例,每个服务发现实例都单独协程运行p.d.Run,
func (m *Manager) startProvider(ctx context.Context, p *Provider) {
m.logger.Debug("Starting provider", "provider", p.name, "subs", fmt.Sprintf("%v", p.subs))
ctx, cancel := context.WithCancel(ctx)
updates := make(chan []*targetgroup.Group)
p.cancel = cancel
go p.d.Run(ctx, updates)
go m.updater(ctx, p, updates)
}同时会协程启动一个 m.updater用于做一些数据整理,然后会触发m.triggerSend 这个 chan
func (m *Manager) updater(ctx context.Context, p *Provider, updates chan []*targetgroup.Group) {
// Ensure targets from this provider are cleaned up.
defer m.cleaner(p)
for {
select {
case <-ctx.Done():
return
case tgs, ok := <-updates:
m.metrics.ReceivedUpdates.Inc()
if !ok {
m.logger.Debug("Discoverer channel closed", "provider", p.name)
// Wait for provider cancellation to ensure targets are cleaned up when expected.
<-ctx.Done()
return
}
p.mu.RLock()
for s := range p.subs {
m.updateGroup(poolKey{setName: s, provider: p.name}, tgs)
}
p.mu.RUnlock()
select {
case m.triggerSend <- struct{}{}:
default:
}
}
}
}在协程 sender 内,m.allGroups 会触发 syncCh 这个 chan,而这个 chan 会被 promethesu 的 scrape 接收处理。
func (m *Manager) sender() {
ticker := time.NewTicker(m.updatert)
defer ticker.Stop()
for {
select {
case <-m.ctx.Done():
return
case <-ticker.C: // Some discoverers send updates too often, so we throttle these with the ticker.
select {
case <-m.triggerSend:
m.metrics.SentUpdates.Inc()
select {
case m.syncCh <- m.allGroups():
default:
m.metrics.DelayedUpdates.Inc()
m.logger.Debug("Discovery receiver's channel was full so will retry the next cycle")
select {
case m.triggerSend <- struct{}{}:
default:
}
}
default:
}
}
}
}整体流程
