goroutine轻量的特点往往被认为是改善程序的解决方案。不幸的是,由于goroutine上下文切换消耗,goroutine的不当使用反而会降低程序的性能。
背景&测试
背景:对超过10k的数据文档进行计算
下面给出第一个待测试的算法逻辑
算法1
listings <- GetListings()
For each chunk of 1000 in listings
Start goroutine
For each listing in chunk
score <- CalculateMatching(listing, lead)
Add the score to the bulk object
Bulk insert the 1000 scores of the chunk
其中每1000个文档启动一个goroutine,基准测试如下
name time/op LeadMatchingGenerationFor10000Matches-4 626ms ± 6%
让我们在计算中使用更多的goroutine对每个文档单独goroutine计算。修改如下
算法2
// we get all listing that are around of this kind of profile
listings <- GetListings()
For each chunk of 1000 in listings
Start goroutine
For each listing in chunk
Start goroutine
score <- CalculateMatching(listing, lead)
Add the score to the bulk object
Bulk insert the 1000 scores
基准测试如下:
name time/op LeadMatchingGenerationFor10000Matches-4 698ms ± 4%
现在结果慢了11%,但是这是预期之中的,实际上,以上场景是纯数学计算,因此导致go调度器没有机会在新goroutine中发挥作用。
由于上下文切换而导致的Goroutine延迟
我们需要分析go调度器如何运行goroutine。我们首先分析”算法1“。我们将使用GODEBUG运行基准测试。
GODEBUG=schedtrace=1 go test ./... -run=^$ -bench=LeadMatchingGenerationFor10000Matches -benchtime=1ns
schedtrace=1 将会打印go调度器每ms的调度事件。这里是一部分trace信息
gomaxprocs=2 idleprocs=1 runqueue=0 [0 0] gomaxprocs=2 idleprocs=1 runqueue=0 [0 0] gomaxprocs=2 idleprocs=1 runqueue=0 [0 0] gomaxprocs=2 idleprocs=0 runqueue=1 [0 0] gomaxprocs=2 idleprocs=2 runqueue=0 [0 0] gomaxprocs=2 idleprocs=2 runqueue=0 [0 0]
gomaxprocs 显示可用的处理器数量,idleprocs显示空闲处理器数量, runqueue显示全局队列中等待的goroutine数量,([0 0]) 显示了每个单独处理器本地队列中等待的goroutine数量。
我们可以发现这里goroutine的使用率不高,处理器也不繁忙,我们想知道我们是否需要增加更多的goroutine来利用这些闲置资源。让我们尝试对”算法2“进行相同的分析,并为每个文档使用单独的goroutine来计算。
gomaxprocs=2 idleprocs=0 runqueue=645 [116 186] gomaxprocs=2 idleprocs=0 runqueue=514 [77 104] gomaxprocs=2 idleprocs=0 runqueue=382 [57 64] gomaxprocs=2 idleprocs=0 runqueue=124 [57 88] gomaxprocs=2 idleprocs=0 runqueue=0 [28 17] gomaxprocs=2 idleprocs=1 runqueue=0 [0 0]
现在我们可以发现大量goroutine在全局和本地队列中,处理器也处于繁忙状态。但是很快处理器就再次恢复空闲状态。我们可以通过tracer分析goroutine。
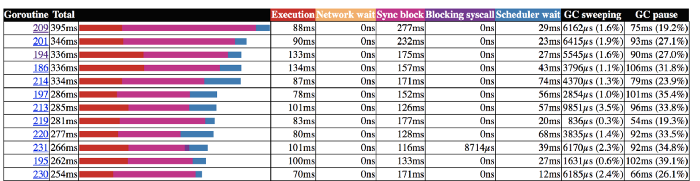

goroutine 209 等待服务器返回
如我们所见,大多数goroutine在批量记录( bulk record)时等待服务器的响应。 这是我们应该集中精力改进并利用这一等待时间的地方。 这就是为什么我们为批量记录文档单独创建goroutines的原因。
我们现在也可以理解在计算中增加goroutine并没有产生收益,因为计算是没有等待的(不同于上面提到的批量记录时存在网络等待),系统无法让当前goroutine暂停来让另一个goroutine运行。
总结
综上在存在io等待的场景可以通过基准测试的方式增加goroutine数量来提升程序性能,纯计算场景建议配合基准测试基于或低于cpu数量来设置goroutine数量以获得最佳性能。